


Adapting Chain of Contradiction (CoC) for Sarcasm Detection
Check out the official PDF for Adapting Chain of Contradiction (CoC) for Sarcasm Detection
⚪ Overview
This project extends SarcasmBench, a benchmark for evaluating Large Language Models (LLMs) on sarcasm detection, by incorporating Chain of Contradiction (CoC) prompting. Unlike traditional Chain-of-Thought (CoT) reasoning, CoC explicitly models sarcasm as a contradiction between surface sentiment and true intent. The result is a scalable, reasoning-based prompting method that improves sarcasm classification, particularly for inputs containing direct or overt sarcasm cues.
We evaluate CoC against zero-shot, few-shot, and CoT prompting methods across five benchmark datasets and three LLMs: GPT-4o-mini, LLaMA 3-8B, and Qwen 2-7B. Across these models and tasks, CoC prompting consistently improves recall and F1 score, especially in tweet-style and conversational sarcasm where sentiment mismatches are more pronounced.
⚪ Motivation
Sarcasm is a challenging problem in NLP due to its dependence on tone, sentiment reversal, and pragmatic context. Traditional models (RNNs, CNNs) and even general CoT prompting strategies underperform because they fail to reason about sentiment contradictions explicitly. Inspired by recent work showing LLMs can engage in structured sentiment reasoning, we implement CoC as a three-step prompting pipeline to guide models toward contradiction evaluation, which is core to sarcasm.
⚪ Methodology
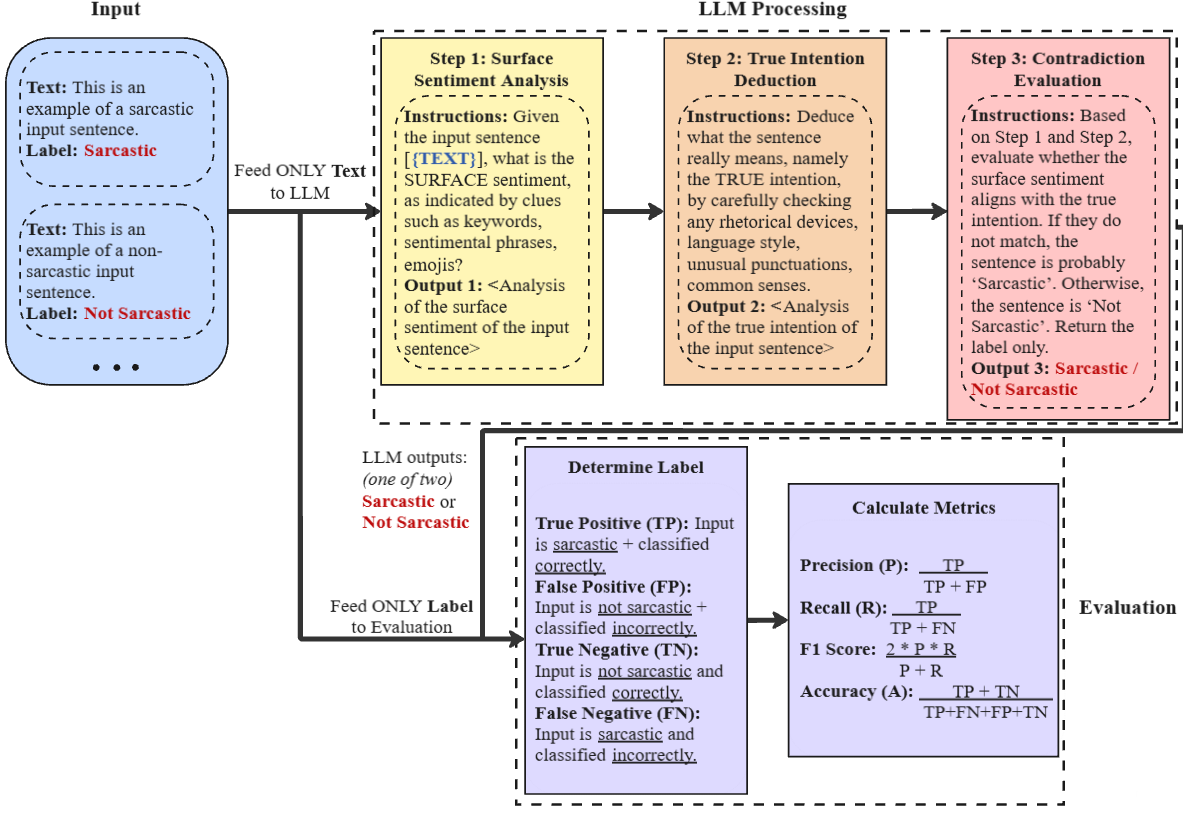
CoC prompting operates in three stages:
- 1. Surface Sentiment Analysis — Identify the literal sentiment via sentiment-bearing keywords or emojis.
- 2. True Intention Deduction — Infer the actual meaning using rhetorical style and common sense.
- 3. Contradiction Evaluation — Classify as “Sarcastic” if there is a mismatch between 1 and 2.
This process is applied in few-shot settings using formatted dialogue prompts. Evaluation spans five sarcasm datasets (IAC-V1, IAC-V2, Ghosh, iSarcasmEval, SemEval 2018) after cleaning, normalization, and emoji token conversion. Models are tested under resource-aware conditions, with GPT-4o-mini (API), LLaMA 3-8B, and Qwen 2-7B (run locally via oLLaMA).
⚪ Results
CoC prompting demonstrated strong empirical performance:
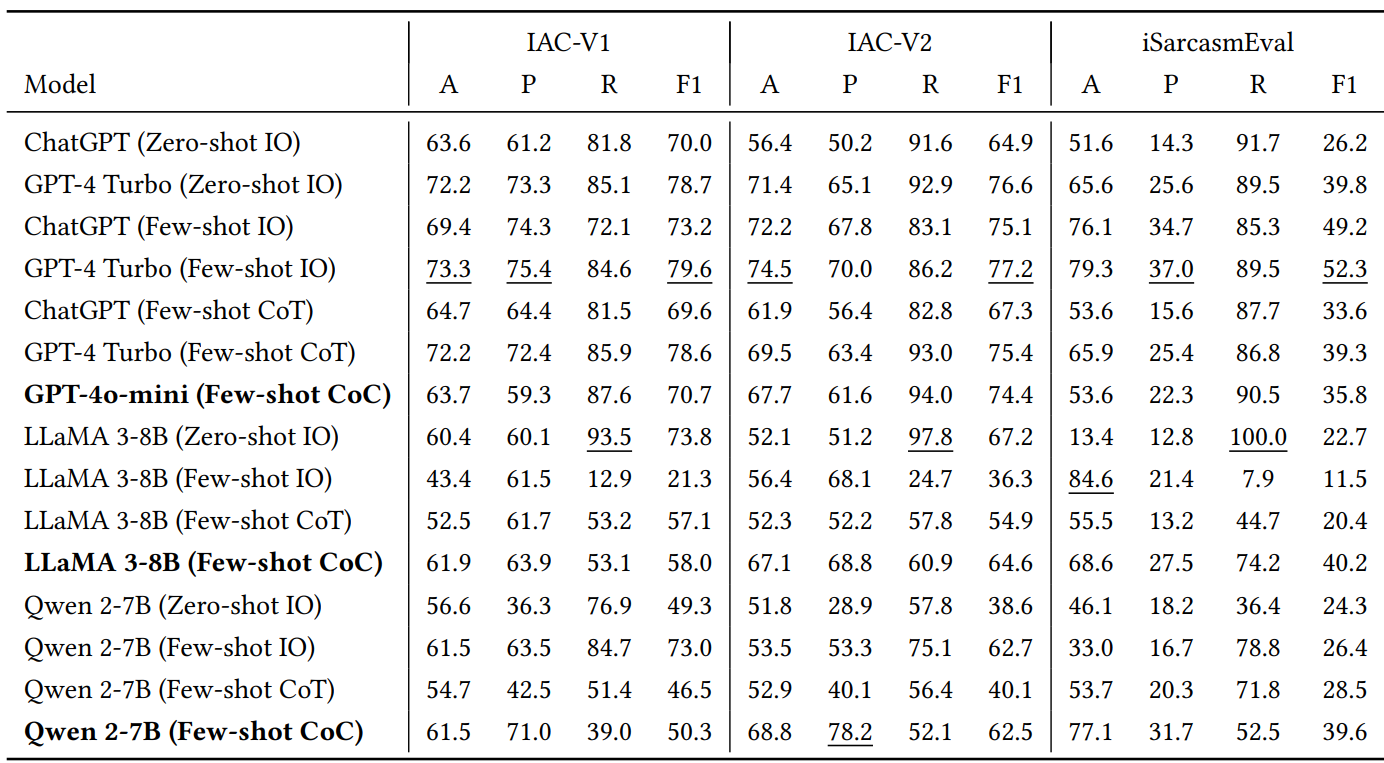
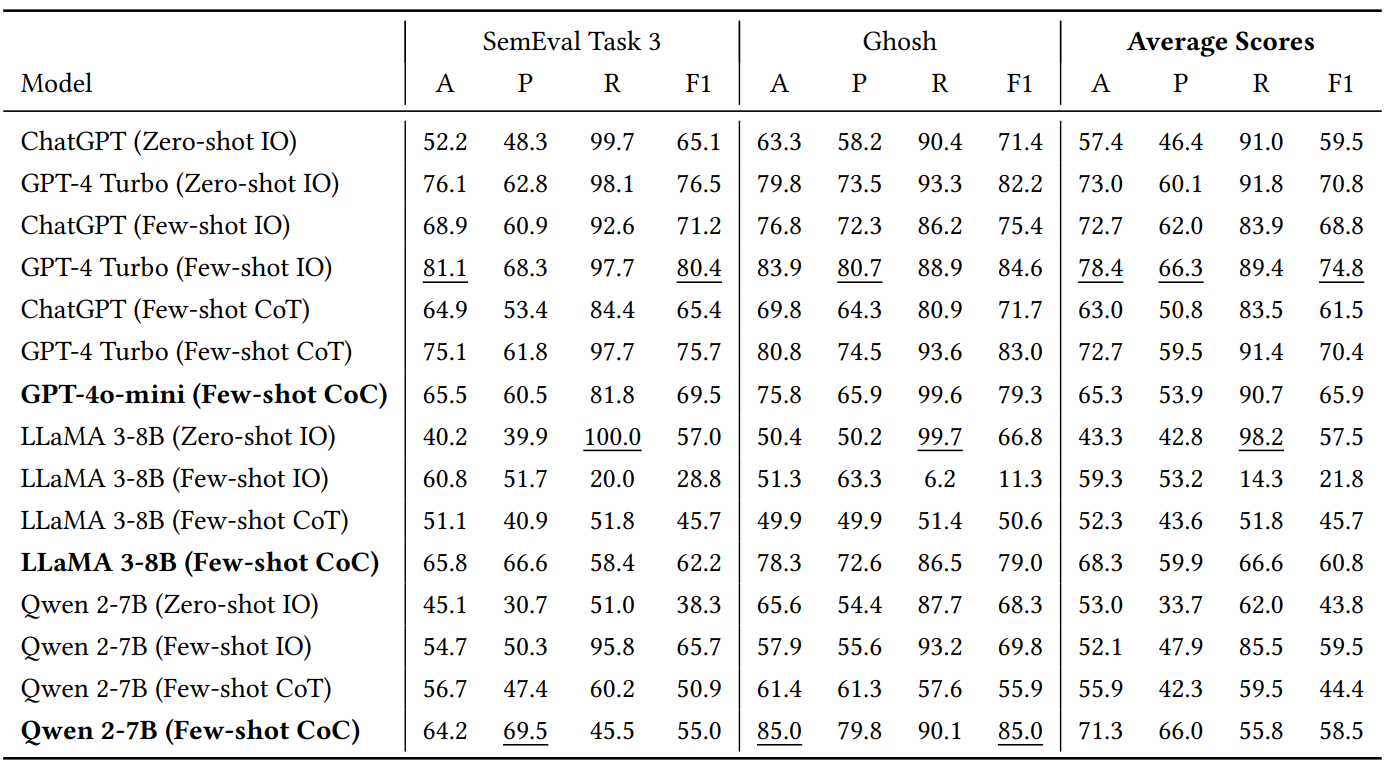
- 4. GPT-4o-mini achieved the highest recall across most datasets (e.g., 94.0% on IAC-V2).
- 5. LLaMA 3-8B and Qwen 2-7B saw massive F1 improvements on tweet-heavy datasets like Ghosh, highlighting CoC’s ability to guide weaker models.
- 6. CoC was most effective on datasets with explicit sarcasm markers and least effective on subtle, author-labeled sarcasm.
- 7. Average F1 gains were most notable on IAC and Ghosh datasets, while SemEval and iSarcasmEval saw marginal improvement.
🔍 Despite modest precision trade-offs, CoC reliably boosted recall, which is crucial for real-world sarcasm detection.
⚪ Challenges & Discussion
- 8. Prompt adherence varied between models. LLaMA occasionally returned open-ended responses instead of labels.
- 9. Subtle sarcasm still eludes CoC due to minimal contextual clues.
- 10. Preprocessing inconsistencies between datasets required additional normalization, especially for emojis.
⚪ Future Work
Future extensions include exploring Graph of Cues (GoC) and Tensor of Cues (ToC), which model multi-modal and higher-order sarcasm features. Reinforcement learning-based prompt tuning and expansion to instruction-tuned models may further improve generalizability. Evaluation on broader domains could confirm whether CoC’s gains are architecture-agnostic.