Improving Adaptive Cruise Control via Curriculum and Anti-Curriculum Reinforcement Learning
Check out the official PDF for Improving Adaptive Cruise Control via Curriculum and Anti-Curriculum Reinforcement Learning
▱▰▱ Abstract: ▰▱▰
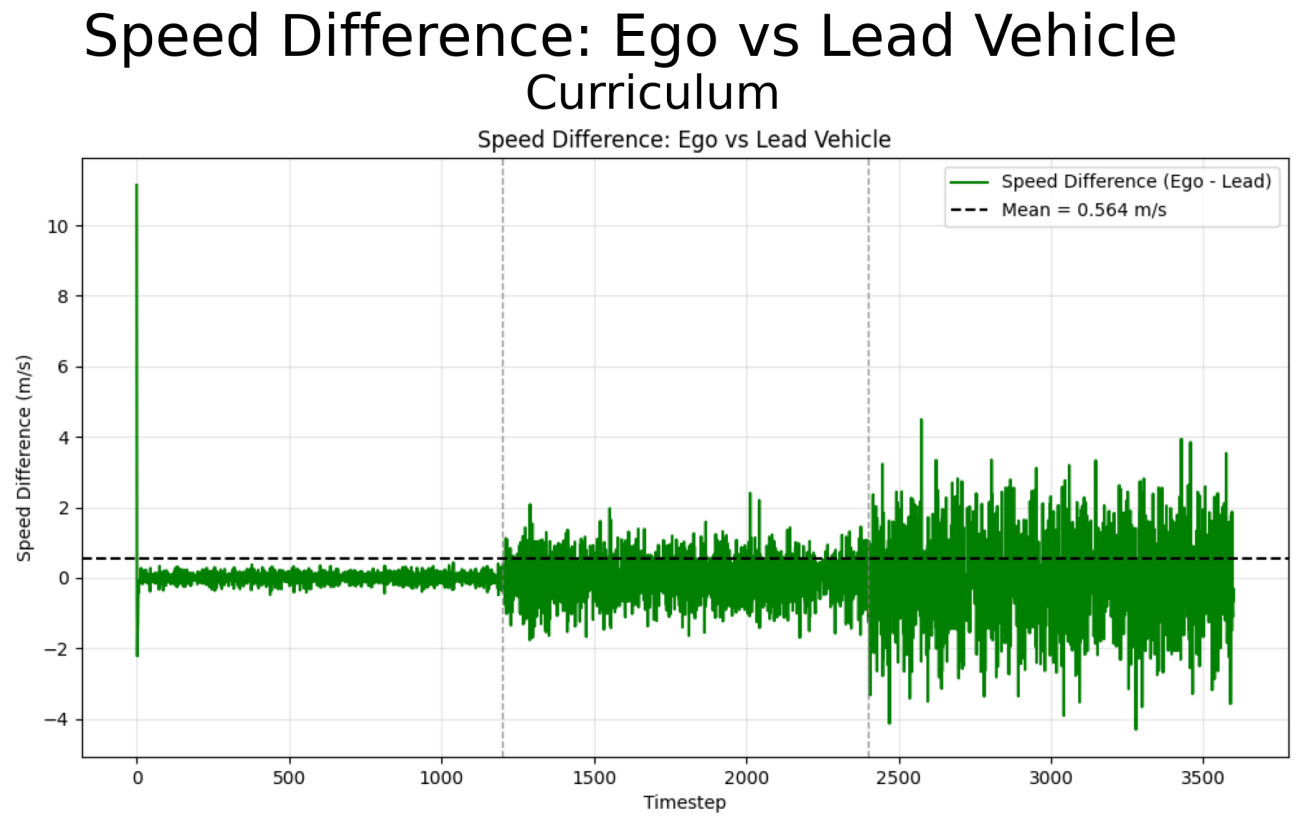
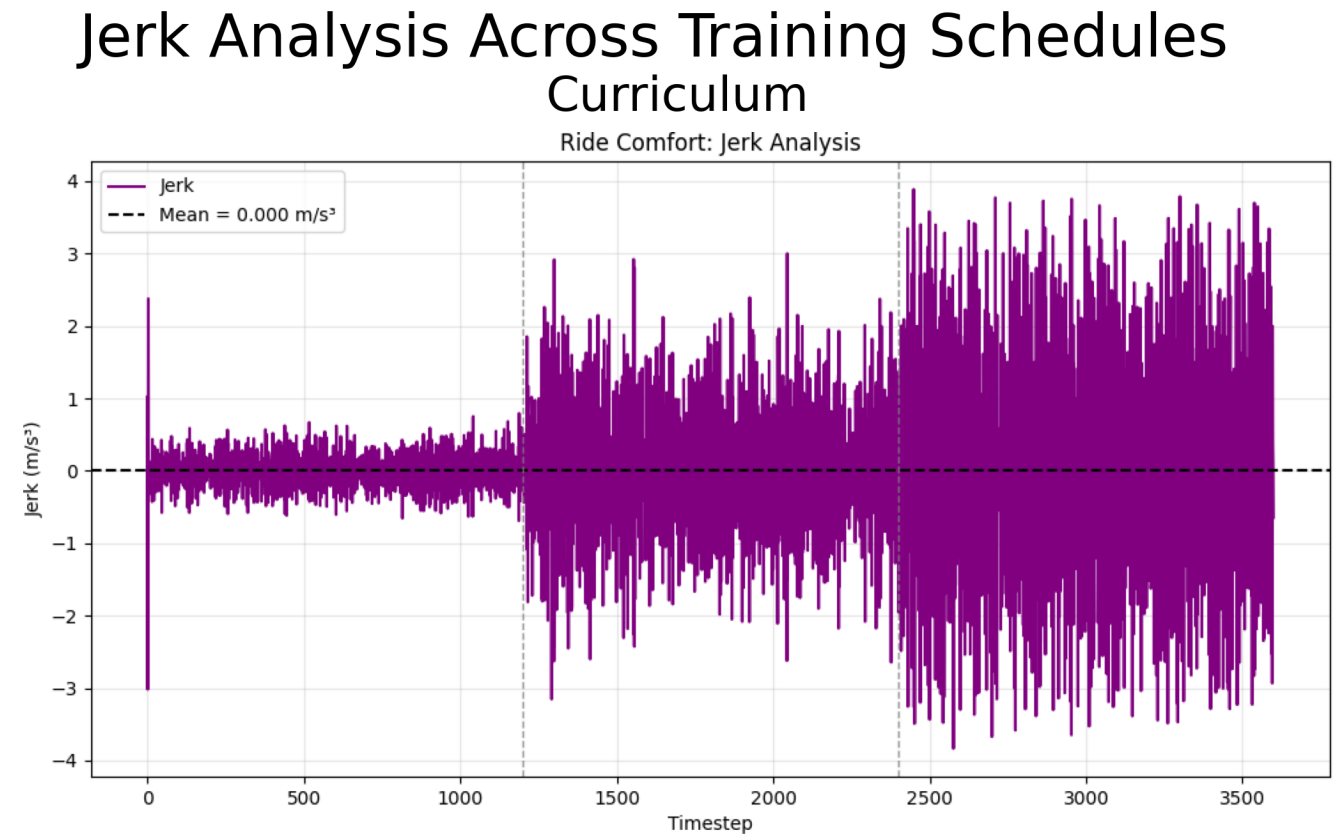
This project applies curriculum learning and anti-curriculum learning to a reinforcement learning-based Adaptive Cruise Control (ACC) environment. The agent learns to maintain safe following distance behind a lead vehicle while minimizing jerk and speed error. Difficulty levels are introduced by generating lead vehicle profiles with increasing variability and aggression in acceleration patterns.
Curriculum learning trains the agent starting from easy profiles progressing to difficult, while anti-curriculum does the opposite. A baseline model is also trained solely on the hardest profile. Evaluation is performed on a 3600-step episode containing all three difficulty levels sequentially.
▱▰▱ Methodology: ▰▱▰
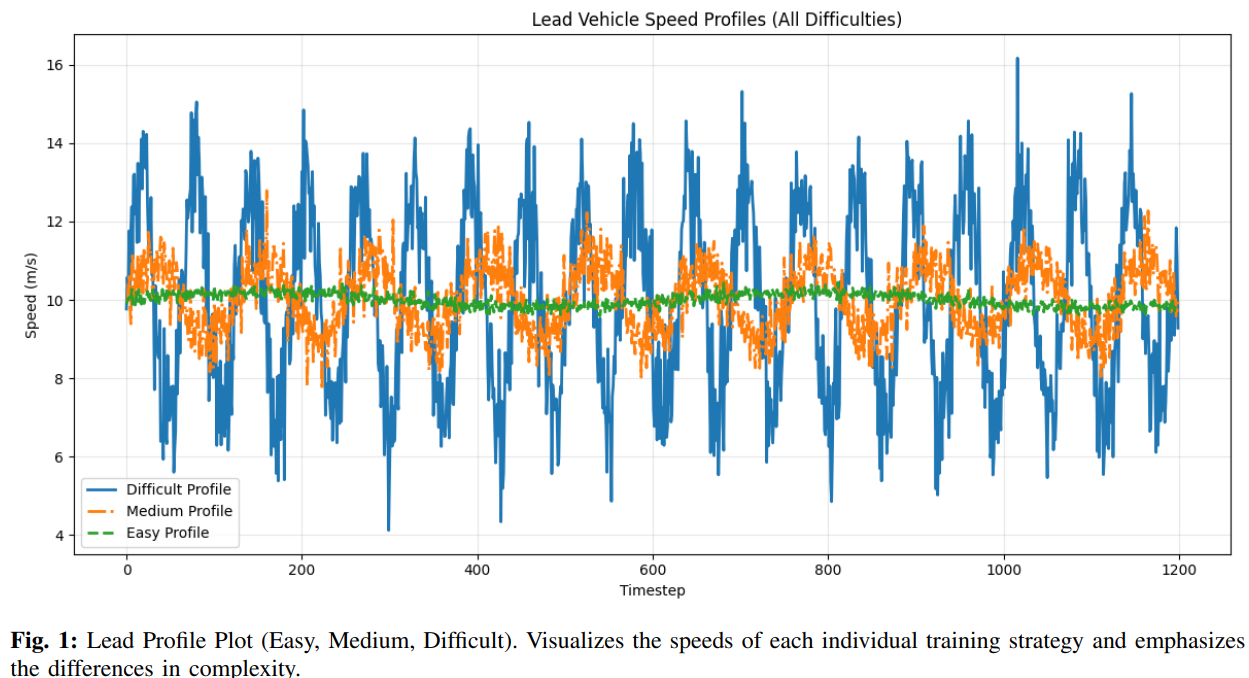
The agent uses a Soft Actor-Critic (SAC) algorithm with a continuous action space. Curriculum stages are defined by generating synthetic lead vehicle velocity sequences of varying difficulty:
- 1. Easy: low acceleration variance, smooth deceleration
- 2. Medium: moderate acceleration and occasional abrupt stops
- 3. Difficult: high variance, aggressive acceleration/deceleration
During training, curriculum and anti-curriculum variants stage the environments differently while keeping hyperparameters consistent. All agents are tested on a held-out evaluation track consisting of 1200 steps from each difficulty class.
▱▰▱ Results: ▰▱▰
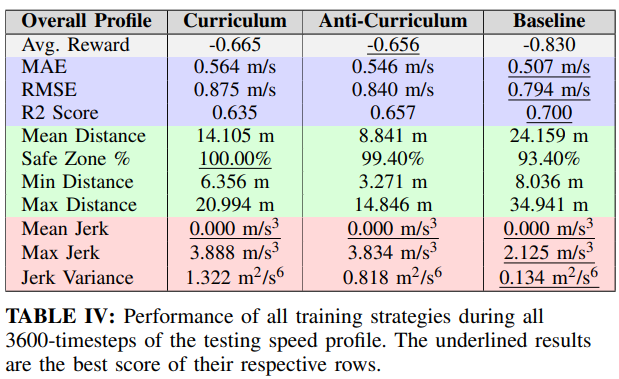
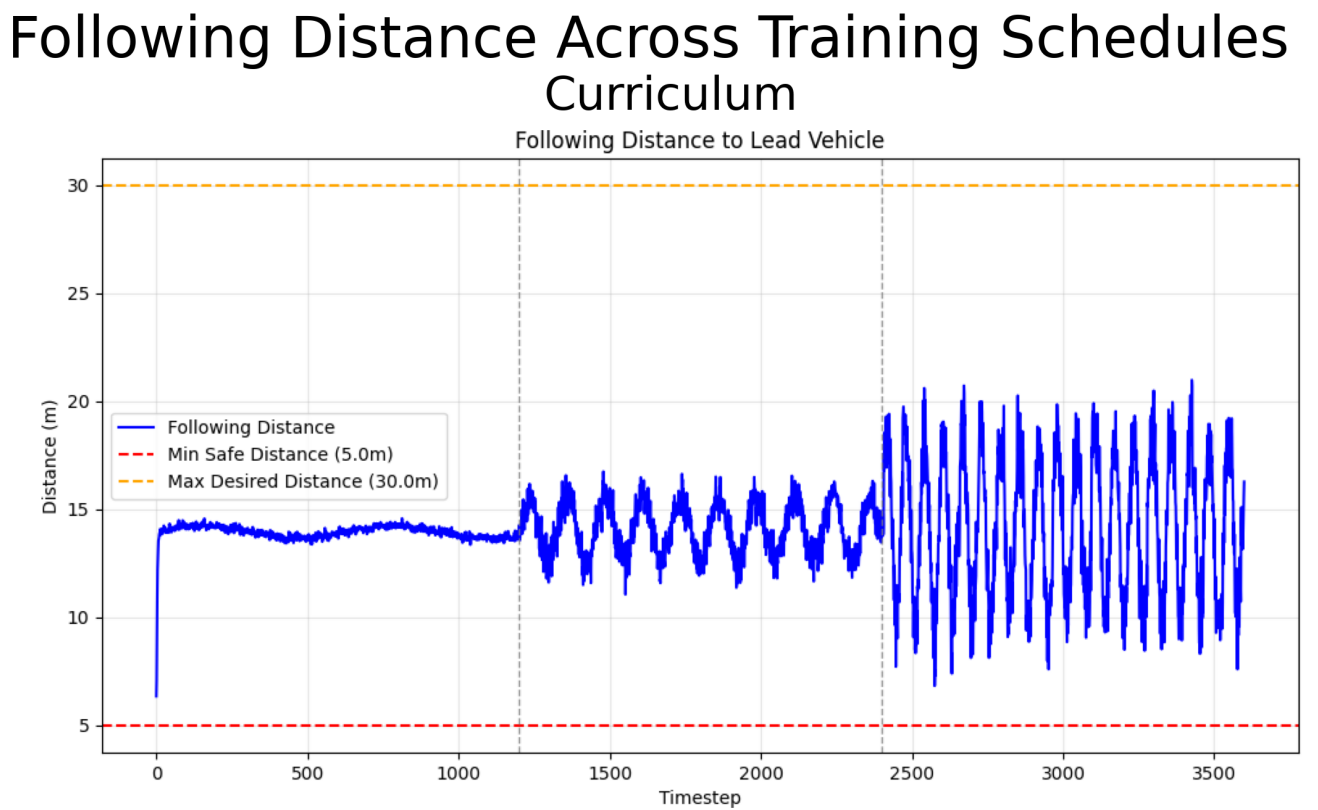
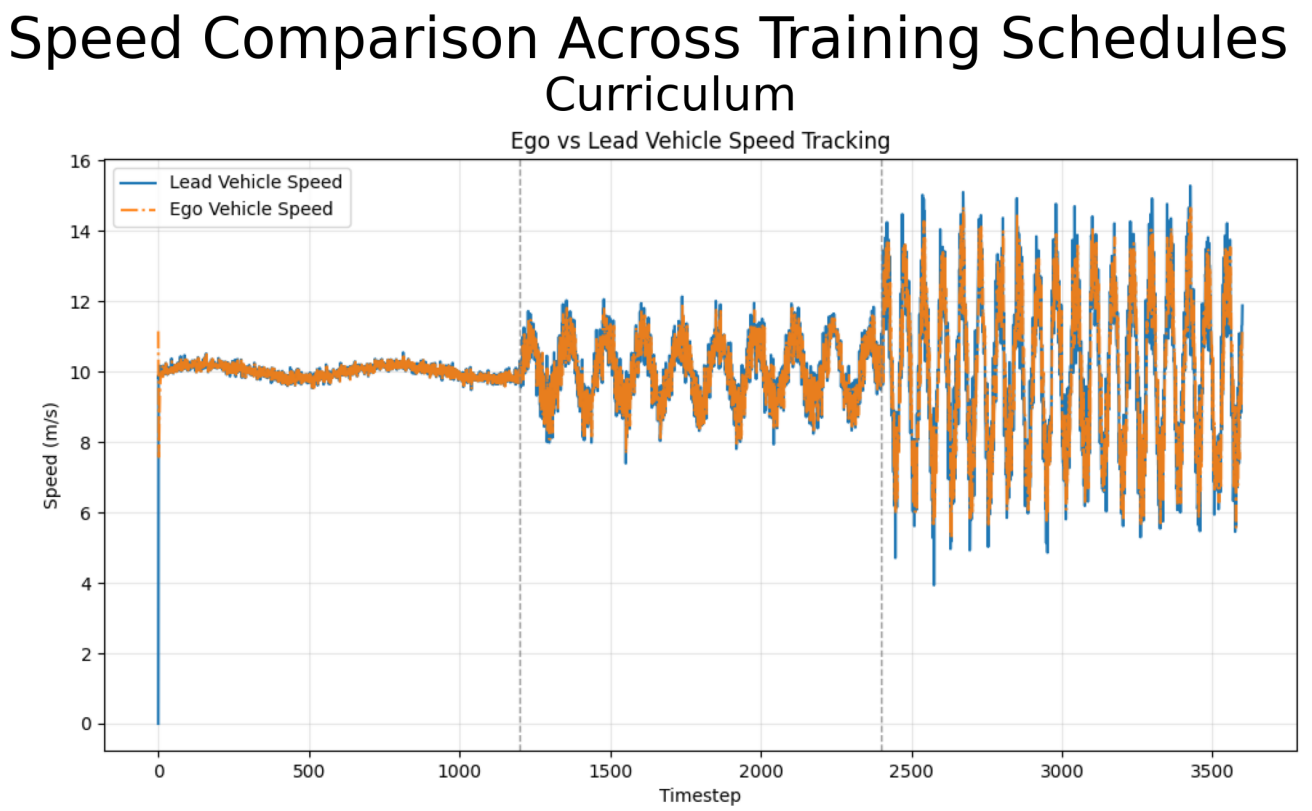
Curriculum learning achieved the best overall performance in average reward, distance error, and time spent in the safety zone. Anti-curriculum learning performed moderately well but struggled in difficult sections. The baseline model underperformed, showing the benefit of incremental exposure to harder environments.
▱▰▱ Discussion: ▰▱▰
Curriculum learning enabled smoother policy formation, while anti-curriculum often forced premature convergence due to exposure to high-variance states too early. All agents showed difficulty in jerk minimization on difficult profiles, suggesting reward shaping improvements.
▱▰▱ Future Work: ▰▱▰
Future improvements include experimenting with PPO or TD3 algorithms, redesigning the reward function to better penalize jerk, and introducing real-world driving profiles for robustness testing.
▱▰▱ Link: ▰▱▰
💻 GitHub https://github.com/jkglaspey/EEL6938-Final-Project-Curriculum-Learning-ACC